如何在 CSDN 上用 Python 战胜人狗大战的挑战?
在 CSDN 上,有一个备受关注的挑战——人狗大战。这是一个关于人工智能的竞赛,旨在让机器能够像人类一样理解和处理自然语言。在这个挑战中,Python 作为一种强大的编程语言,被广泛应用于各种解决方案中。那么,如何在 CSDN 上用 Python 战胜人狗大战的挑战呢?将从以下几个方面进行探讨。
数据准备
在人狗大战中,数据是至关重要的。我们需要收集大量的文本数据,包括各种领域、书籍、网页等。这些数据将用于训练我们的模型。我们需要对这些数据进行预处理,包括清理噪声、分词、标记化等操作。我们需要将数据分为训练集、验证集和测试集,以便进行模型的训练和评估。
模型选择
在人狗大战中,有许多不同的模型可供选择,例如神经网络、循环神经网络 (RNN)、长短时记忆网络 (LSTM) 和门控循环单元 (GRU) 等。这些模型都具有不同的特点和优势,我们需要根据具体情况选择合适的模型。RNN 和 LSTM 模型在处理序列数据方面表现出色,因此在人狗大战中被广泛应用。
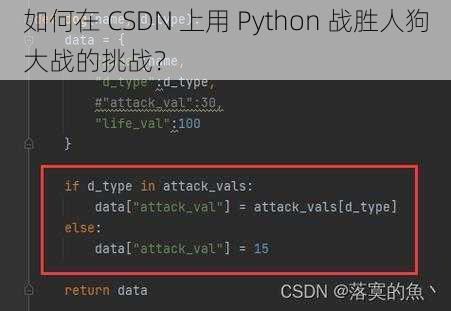
模型训练
在选择好模型后,我们需要进行模型的训练。训练过程包括以下几个步骤:
1. 定义模型参数:我们需要定义模型的超参数,例如学习率、层数、神经元数量等。
2. 数据预处理:我们需要将预处理后的数据转换为模型可接受的格式,例如将文本数据转换为向量。
3. 模型训练:我们使用训练集对模型进行训练,更新模型的参数,以最小化损失函数。
4. 模型评估:我们使用验证集对训练好的模型进行评估,以确定模型的性能。
5. 模型调整:如果模型的性能不够理想,我们可以调整模型的参数或尝试其他模型。
模型评估
在训练好模型后,我们需要对模型进行评估,以确定模型的性能。评估指标通常包括准确率、召回率、F1 值等。我们可以使用测试集对模型进行评估,并与其他模型进行比较。
模型优化
为了提高模型的性能,我们可以采取以下措施:
1. 增加数据量:更多的数据可以提高模型的泛化能力。
2. 增加模型复杂度:增加模型的层数或神经元数量可以提高模型的性能,但也可能导致过拟合。
3. 使用正则化:正则化可以防止模型过拟合,例如使用 L1 和 L2 正则化。
4. 模型融合:我们可以将多个模型进行融合,以提高模型的性能。
5. 超参数调整:超参数的选择对模型的性能有很大影响,我们可以使用网格搜索或随机搜索等方法进行超参数调整。
模型部署
在完成模型的训练和评估后,我们需要将模型部署到实际应用中。这包括将模型转换为可执行文件或部署到云平台上,以便用户可以使用模型进行自然语言处理任务。
在 CSDN 上人狗大战的挑战中,Python 是一种非常强大的编程语言,可以用于实现各种解决方案。通过合理的数据准备、模型选择和训练,我们可以训练出性能优异的模型,并在测试集上取得较好的结果。我们还可以通过模型评估和优化,进一步提高模型的性能。将训练好的模型部署到实际应用中,为用户提供更好的服务和体验。
需要注意的是,人狗大战是一个非常具有挑战性的任务,需要大量的计算资源和时间。自然语言处理是一个非常复杂的领域,需要不断地探索和创新。希望能够为读者提供一些启示和帮助,让我们一起在 CSDN 上战胜人狗大战的挑战!